No hemos encontrado resultados relativos a la búsqueda realizada.
Puedes volver a intentarlo de nuevo realizando una nueva búsqueda.
No hemos encontrado resultados relativos a la búsqueda realizada.
Puedes volver a intentarlo de nuevo realizado una nueva búsqueda.
Desarrollo e implantación de sistema de soporte de decisión en líneas de producción de PACKSNAK, S.L.
Por Álvaro Barba García

17 de Nov de 2020 · Informática y TICS
El presente TFM de intervención elabora un plan de acción para Diseñar e Implementar una Aplicación Informática para una empresa ficticia PackSnack, S.L. dedicada al envasado de snacks en diferentes tamaños y referencias. Para ello, dispone de 3 plantas de envasado.
Las plantas actualmente, tienen un control de tiempos muy manuales, ya que los operarios de las líneas de producción, apuntan en papel los tiempos de producción empleados. Dichos tiempos, no se digitalizan, lo que hace que sea imposible consultar o extraer conclusiones de los mismos.
Dicha aplicación, básicamente, será un Sistema de Soporte de Decisión que recogerá datos relacionados con tiempos de producción en las líneas de ensamblado de la compañía, almacenará dichos datos en BBDD y, una vez almacenados, se realizarán trabajos inferenciales con los mismos.
¿Te resulta interesante?
¡Guarda este contenido completo en PDF!
Descarga gratis este contenido y consúltalo cuando lo necesites
1. Introducción
1.1 Contexto
1.1.1 Presentación de la empresa
La compañía PackSnack S.L., es una empresa ficticia, así como todos los datos que se indican sobre la misma a lo largo del documento.
PackSnack S.L., es una empresa dedicada al envasado de snacks en diferentes tamaños y referencias, de su propia marca. Para ello, dispone de 3 plantas de envasado, repartidas en la comunidad de Madrid con 18 Operarios por planta. Cada una de las plantas, tiene tres turnos de trabajo (mañana, tarde y noche), de lunes a viernes.
PLANTAS ENVASADO
1.1.2 Motivación
La Compañía PackSnack S.L., cuenta con un ERP con el que controla los movimientos de materiales en lo referente a las órdenes de producción. Sin embargo, la empresa no cuenta con un sistema fiable de control de tiempos de dichos procesos de envasado. Las plantas actualmente, tienen un control de tiempos muy manual, son los operarios quienes anotan en la hoja de trabajo los tiempos que, posteriormente, se han de digitalizar posteriormente y manualmente por personal administrativo.
El objetivo del presente proyecto de intervención, por tanto, es implementar una App informática que servirá como herramienta de recogida de datos y, posteriormente, de Sistema de Soporte de Decisión, que convertirá los datos en información valiosa para la compañía que le ayude en la toma de decisiones.
1.1.3 Plan de Trabajo
Vamos a distinguir las siguientes fases de forma muy general:
- En primer lugar, deberemos identificar el ámbito de actuación de la App y los datos que queremos medir y que nos aportarán información.
- Diseñaremos las BBDD donde se volcarán aquellos datos introducidos por los operarios y recabados por la aplicación.
- Una vez identificados los datos y diseñada la BBDD, diseñaremos e implementaremos la aplicación que recabe la información introducida por los operarios
- Tras la implementación de la aplicación y pasado un año de tiempo, en un campo más de Data Science, trabajaremos con la inferencia de los datos para sacar conclusiones de los mismos.
1.1.4 Objetivos
- Eliminar duplicidades en el proceso de producción de la compañía
- Tener datos a tiempo real
- Eliminar posibles errores en el proceso
- Fijación de tiempos estándar que nos sirvan de base para la posterior planificación y programación de la producción
- Generar insights para el establecimiento e implantación de sistemas de incentivos para los operarios, una vez definidos los tiempos medios.
2. Identificación del ámbito de actuación y los datos a medir
2.1 Situación actual
Para identificar el ámbito de actuación y los datos que necesitan medir, vamos previamente a definir los siguientes aspectos de la situación actual del funcionamiento de los procesos de trabajo en las plantas de envasado de PackSnack, S.L.:
- Proceso completo actual del trabajo relativo a la realización de las Ordenes de Producción
- Documento relativo al proceso relativo a la realización de las Ordenes de Producción
2.1.1 Proceso Actual
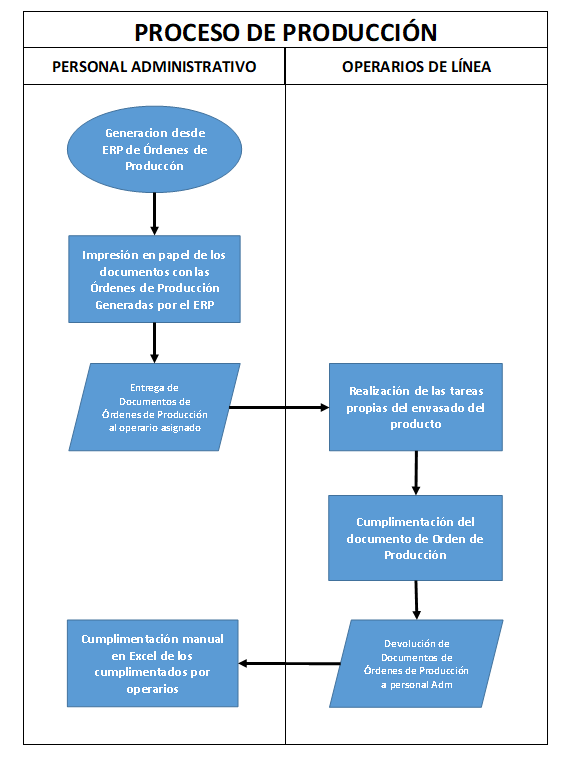
Nuestra App gráfica se centrará en la mejora de las siguientes Operaciones relativas al Proceso de Producción de PackSnack, S.L.:
- Impresión en papel de los documentos con las Órdenes de Producción Generadas por el ERP – esta actividad será suprimida del proceso. En lugar de la impresión, el personal administrativo, cargará las ordenes de producción en un formato .csv, en una BBDD que los operarios podrán consultar posteriormente desde la App situada en la planta de producción
- Entrega de los documentos de Órdenes de Producción al operario asignado – esta actividad será suprimida del proceso igual que el caso anterior.
- Realización de las tareas propias del envasado del producto – esta actividad se seguirá realizando como hasta ahora, ya que no forma parte del ámbito de aplicación del proyecto. Sin embargo, cabe destacar que cada una de las órdenes de producción son realizadas por dos operarios que formar un grupo de trabajo.
- Cumplimentación del documento de Orden de Producción – esta actividad será modificada, ya que, en lugar de cumplimentar el documento físico, lo hará sobre una pantalla en la que tendrá la App creada.
- Devolución de los documentos de Órdenes de Producción al personal Adm – esta actividad será suprimida del proceso, ya que directamente finalizará la Orden de Producción una vez rellenados los datos requeridos.
- Cumplimentación manual en Excel de los datos cumplimentados por los operarios – esta actividad será suprimida del proceso, ya que directamente los operarios al finalizar la orden de producción con los datos rellenados en la App, éstos se almacenarán en la BBDD.
2.1.2 Proceso tras desarrollo e implantación de la App
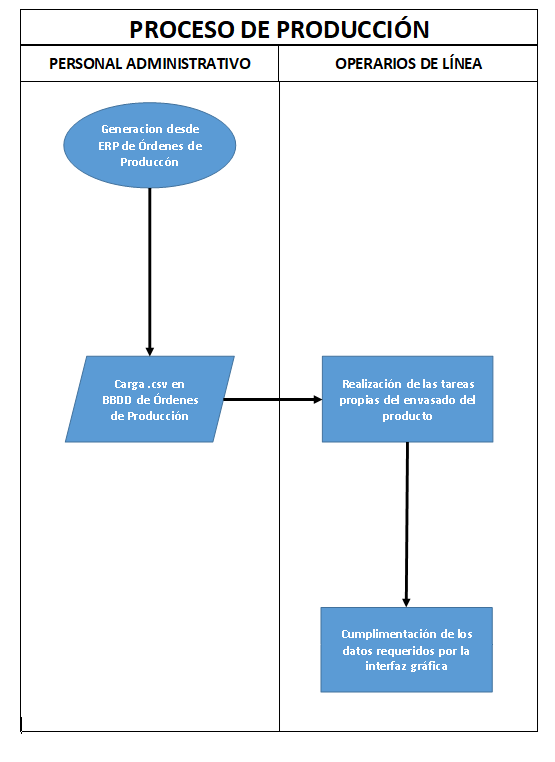
Como podemos observar, la mejora está en la reducción de operaciones del proceso, eliminar las actividades duplicadas y en la correcta recolección de los datos a tiempo real.
2.1.3 Documento
PackSnack S.L. cuenta con un sistema muy rudimentario de recogida de datos. Los operarios, anotan en el documento de orden de producción emitido por el ERP, los tiempos referidos al proceso de envasado.
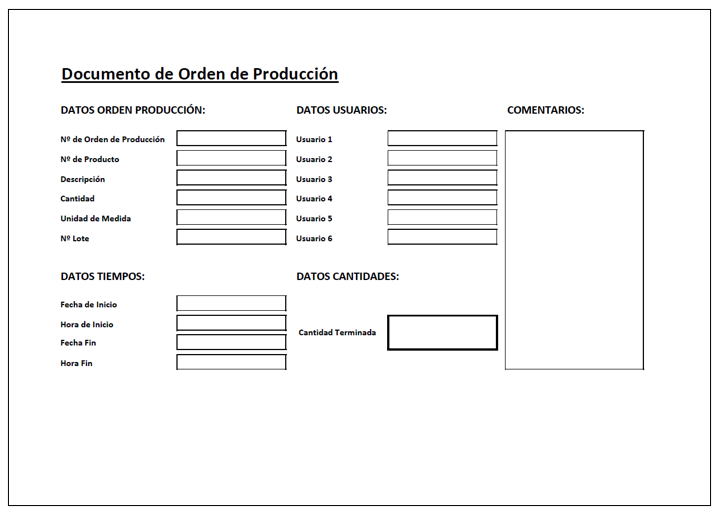
Dicho documento, nos puede servir de guía para ver qué datos son los que la compañía necesita medir. Vamos a analizar el documento:
DATOS ORDEN PRODUCCIÓN: hace referencia a datos generales de la orden de producción. Estos datos son datos No Editables, es decir, son datos pertenecientes a la orden de producción y que salen directamente del ERP.
- Nº de Orden de Producción
- Nº de Producto
- Descripción
- Cantidad
- Unidad de Medida
- Nº Lote
DATOS TIEMPOS: son campos Editables y que por lo tanto rellenarán los operarios
- Fecha de Inicio
- Hora de Inicio
- Fecha Fin
- Hora Fin
DATOS USUARIOS: datos Editables en ellos que se rellenarán los códigos de usuario que realiza la orden.
- Usuario 1
- Usuario 2
- Usuario 3
- Usuario 4
- Usuario 5
- Usuario 6
DATOS CANTIDADES: datos Editables
- Cantidad Terminada
COMENTARIOS: cualquier comentario o incidencia relativas a la orden de producción
3. Diseño de BBDD y tablas
La Base de datos será una Base de Datos Relacional con 5 tablas maestras:

4. Diseño App que recoja los datos
4.1 Proceso Diseño código
4.1.1 Librerías

Tkinter como biblioteca gráfica para el diseño de la App y sqlite3 para poder crear, eliminar y actualizar bases de datos desde Python.
4.1.2 Diseño de la App
4.1.2.1 Raíz de la App

Definimos la variable raíz como el contenedor principal de nuestra App, añadimos un título, le decimos que se vea en pantalla completa y le añadimos el logo de la compañía y, por último, con el método mainloop(), lo que hacemos es decir que no se cierre el contenedor, de forma que hace un bucle con el código que lo mantiene abierto.
4.1.2.2 Frames de la App

Definimos 2 frames dentro de la raíz.
4.1.2.3 Título de la App

Definimos el título en una label, dentro del primer frame que habíamos creado, y le damos un formato que queremos. Por otro lado, los situamos dentro de la primera fila y primera columna de la grid en la que los hemos convertido con el método .grid del código
4.1.2.4 Menús de la App
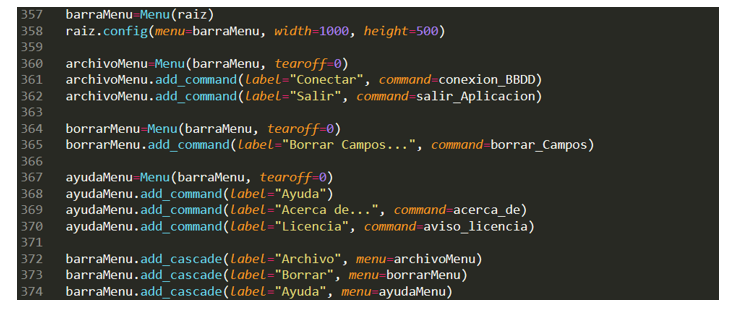
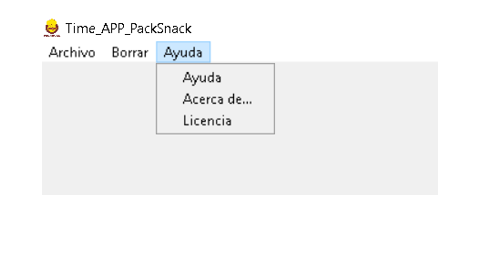
Añadimos una barra de menú dentro de la raíz de la App. Esta barra de menú tendrá 3 menús con sus correspondientes “submenús”:
- Archivo:
- Conectar – estará relacionado con la función conexión_BBDD, que conecta con la BBDD.
- Salir – servirá para salir de la aplicación con la función salir_Aplicacion.
- Borrar:
- Borrar campos – servirá para borrar los campos introducidos en la App con la función borrar_Campos.
- Ayuda:
- Acerca de – activará un mensaje usando la función acerca_de.
- Licencia – activará un mensaje usando la funcion aviso_licencia.
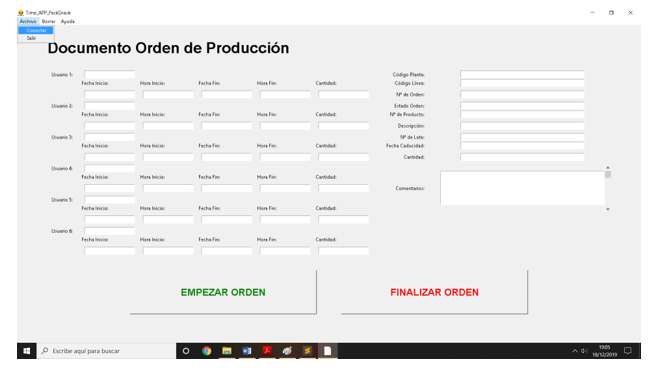
4.1.2.5 Campos de la App
La App tendrá los siguientes campos, que coincidirán con los campos de la tabla maestra de Ordenes_Produccion de la BBDD que habíamos diseñado
Un ejemplo del código utilizado para definir los campos es:

Todos los campos se componen del nombre del campo y de la celda vacía en la que el operario rellenará con los datos:
- Nombre: lo hacemos creando una etiqueta (label) dentro del primer frame que creamos anteriormente y le damos un valor texto con el nombre del campo. Por otro lado, lo colocamos dentro de la parrilla en la que dividimos el frame con el método .grid, donde corresponda
- Celda: lo hacemos creando una Entry, que colocaremos justo al lado de la etiqueta que creamos anteriormente. Por otro lado, definimos una variable en la que se almacenará el texto que el operario introduzca en ella
La mayoría de los campos de la App son iguales, salvo el campo comentarios:

El campo comentarios, es un campo de tipo texto en vez de una entry. Este campo, tendrá una capacidad de introducir datos, mucho mayor que el resto. Además, le hemos colocado una barra de scroll con Scrollbar
4.1.3 Botones de la App
La App tendrá dos botones:
- Empezar orden: servirá para empezar una nueva orden de producción. Definiremos más en profundidad en la seccion de funcionalidades de la App.
- Finalizar orden: servirá para finalizar una orden de producción que esté en marcha. Definiremos más en profundidad en la seccion de funcionalidades de la App.
Este es el código que define los dos botones:

4.1.4 Funcionalidades de la App
La App cuenta con las siguientes funcionalidades o funciones:
4.1.4.1 salir_Aplicacion()

Esta función lanzará un mensaje con una cuestión de sí y no. En caso de que pulsar sí, la APP se cerrará
4.1.4.2 borrar_Campos ()

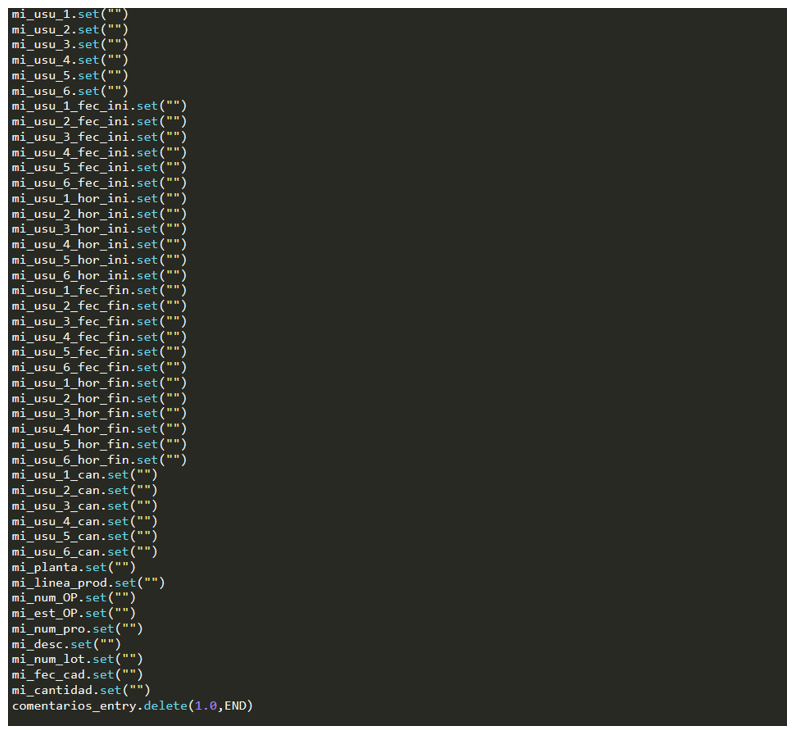
Esta función, lanzará un mensaje con una cuestión de sí y no. En caso de que pulsar sí, rellenará TODOS los campos con un valor vacío, por lo tanto, los borrará
4.1.4.3 acerca_de ()

Esta función lanzará un mensaje de información del nombre y versión de la APP
4.1.4.4 aviso_licencia ()

Esta función lanzará un mensaje de información de la licencia de la APP
4.1.4.5 Conexión_BBDD()
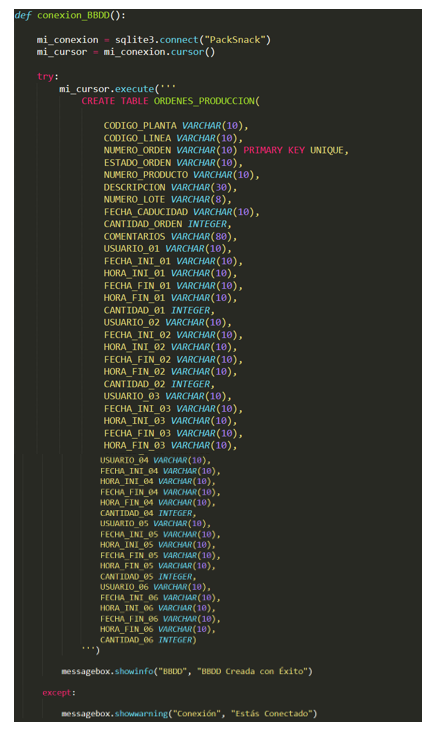
Esta función creará la tabla de órdenes de producción en caso de ser la primera vez que conectamos. Crea todos los campos, con su tipo de dato y su longitud
4.1.4.6 empezar_Orden
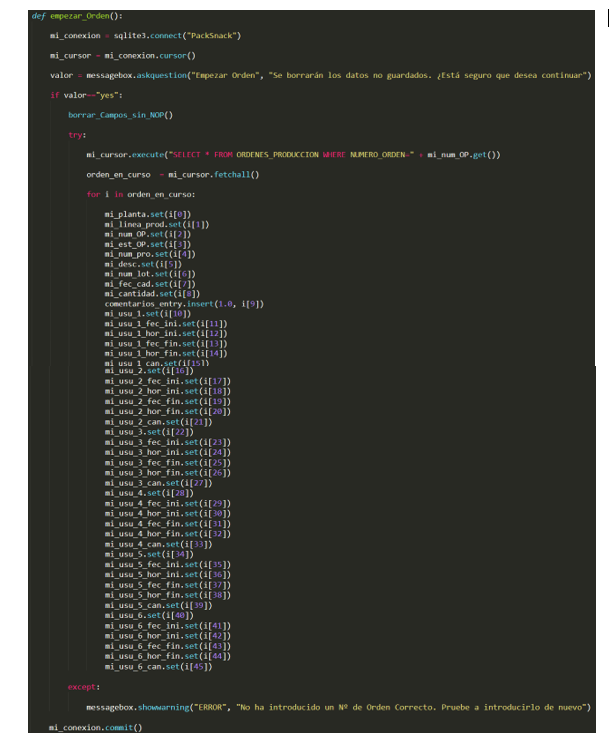
Esta función lanzarlo que hace es crear una consulta a la tabla de la BBDD del número de orden que hayamos introducido en el campo Nª de Orden
4.1.4.7 finalizar_Orden
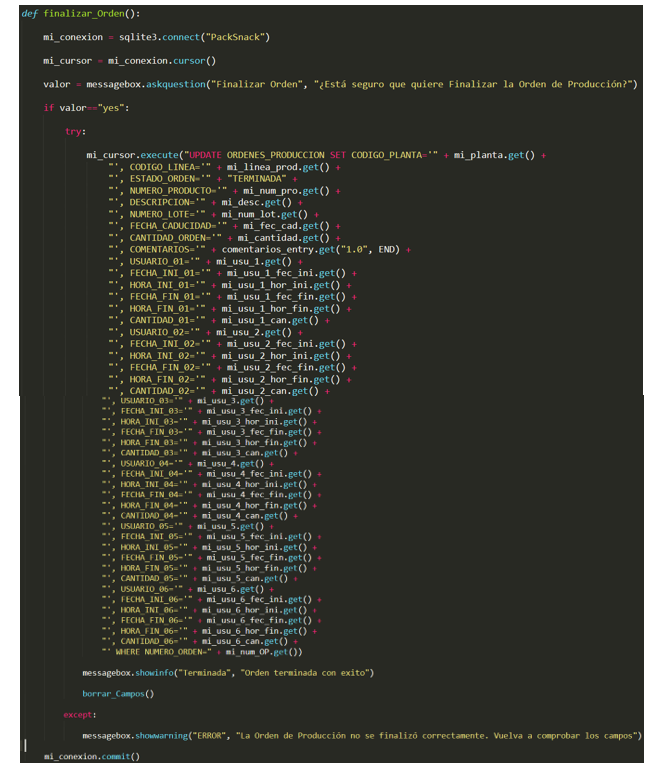
Esta función lo que hace es actualizar con los valores introducidos en los campos la tabla de órdenes de producción.
5. Ejemplo completo paso a paso del nuevo proceso de trabajo
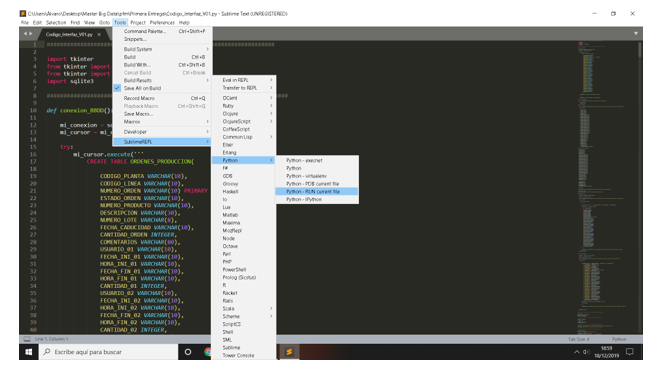
5.1 Arrancar APP
Abrir el archivo Codigo_App_V01 en Sublime Text
Ruta > Tools / SublimeREPL / Python / Python – RUN current file
5.2 Conectar / Crear BBDD
Una vez abierta la APP, hemos de conectar o crear, si es la primera vez que la abrimos, la BBDD
Ruta > Archivo / Conectar
Se creará un archivo de BBDD en el directorio donde hayamos abierto la APP con el nombre PackSnack
5.3 Abrir BBDD e importar Ordenes Producción
Este trabajo corresponderá al personal administrativo
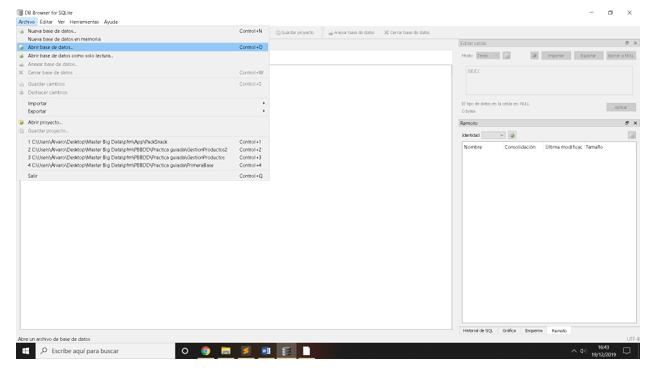
Abrir el archivo PackSnack con DB Browser (SQLite)
Ruta > Archivo / Abrir base de datos…
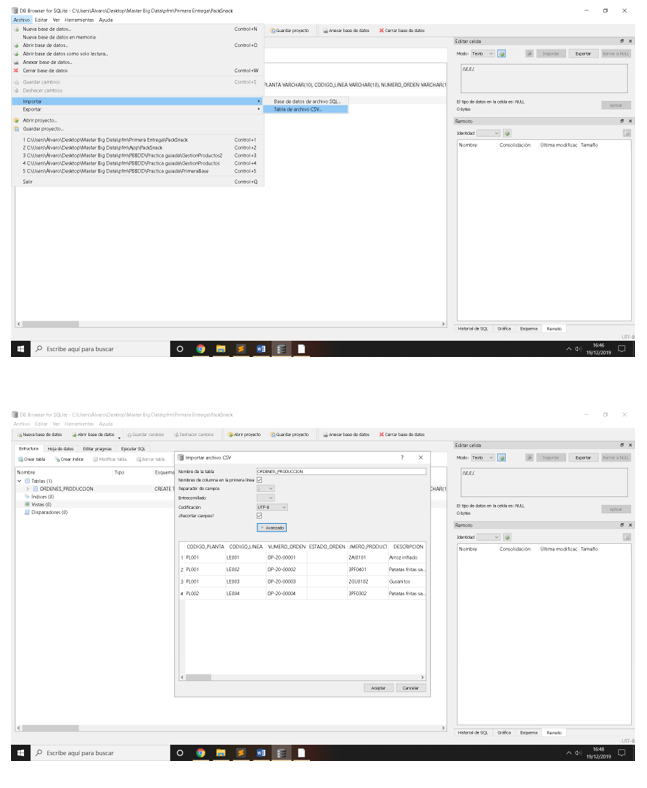
Importar .csv ORDENES_PRODUCCION
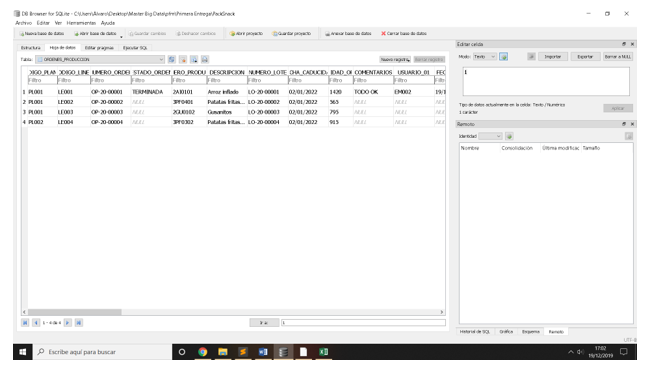
Ruta > Archivo / Importar / Tabla de archivos CSV… / Seleccionar el Archivo ORDENES_PRODUCCION.csv / Abrir / Aceptar (con las opciones de la imagen)
Guardar los cambios en la BBDD
5.4 Empezar Orden
Este trabajo corresponderá al operario de planta
Rellenar con el número de orden a empezar en el campo Nº de Orden de la APP y pulsar el botón EMPEZAR ORDEN
Se rellenarán los datos originales de la orden
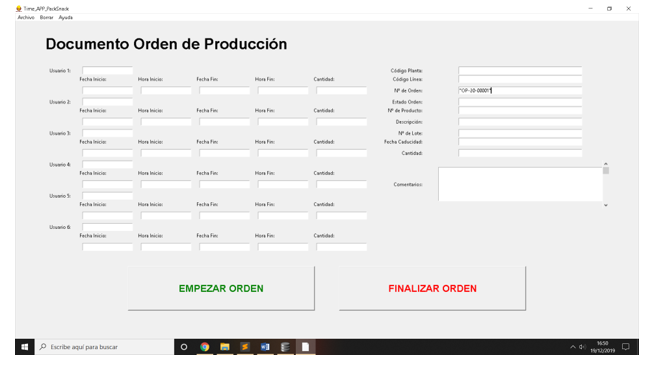
5.5 Cumplimentar los datos de usuario y finalizar orden
Este trabajo corresponderá al operario de planta
Cumplimentar los datos relativos a la realización de la orden y pulsar en finalizar orden
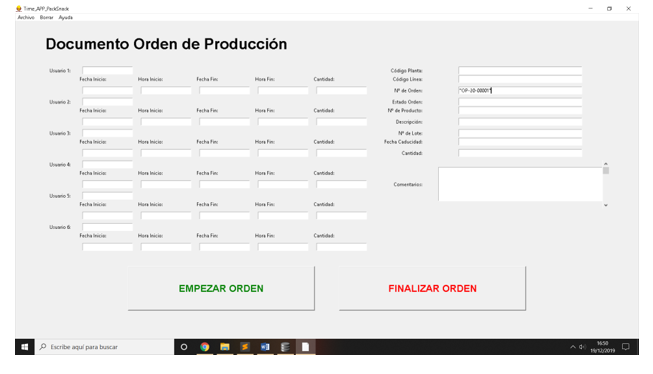
Se habrán actualizado los datos de la BBDD
6. Estadística Inferencial de los datos
6.1 Creación de Fichero RStudio y carga de librerías
Creamos el fichero de RStudio e importamos las librerías necesarias para gestionar los datos:

6.2 Extracción e Importación de datos recogidos de BBDD
Vamos a extraer desde DB Brower las tablas de la Base de datos a archivos .csv para poder trabajar con ellos posteriormente en Rstudio:
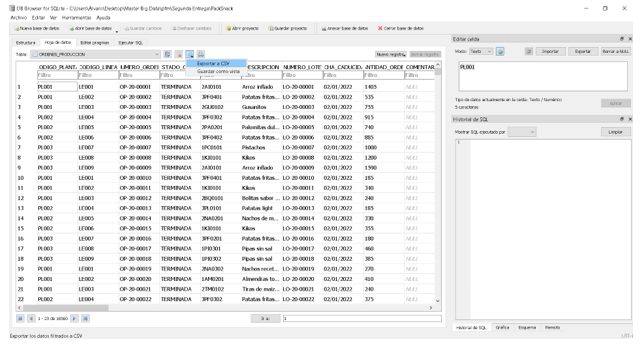
Guardaremos todos los datos en la carpeta Tablas_BBDD
A continuación vamos a importar en el archivo de RStudio que habremos creado previamente, los datos archivos .csv y almacenamos cada uno en una variable:

6.3 Transformación y Limpieza de Datos
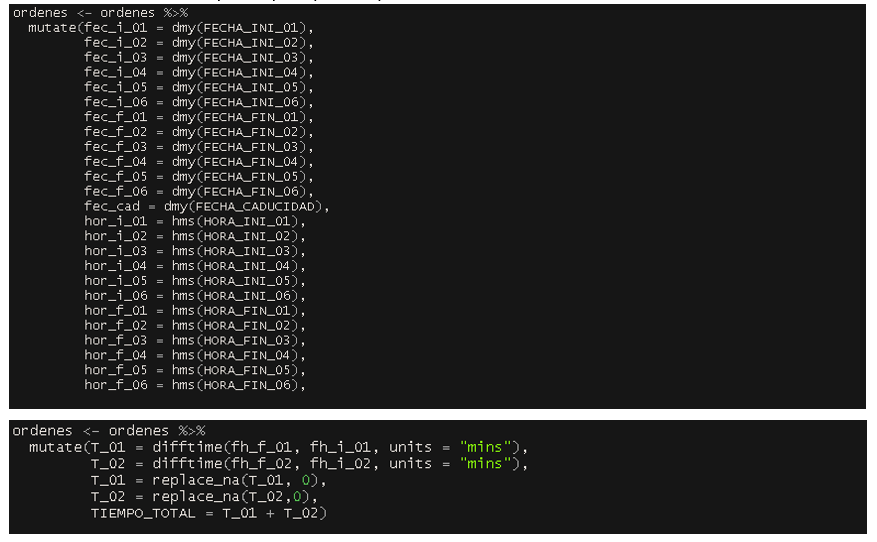
6.3.1 Fecha y Hora a las Columnas de la tabla Órdenes
Para aquellas columnas de la tabla de Órdenes que recogen la información de los tiempos de producción, es decir, las columnas de fecha y hora, les vamos primero a dar un formato de fecha y hora, que perdieron al importar las tablas a RStudio, y, después, vamos a unificar estas columnas en una sola con un formato de fecha y hora para poder operar con esta columna
6.3.2 Unir tabla de Órdenes con tabla de Usuarios
Vamos a unir estas dos tablas usando un join, de modo que quitamos la información duplicada de los usuarios ya que la columna Usuario_01 y Usuario_02, pertenecen al mismo grupo de trabajo, al igual que Usuario_03 y Usuario_04.

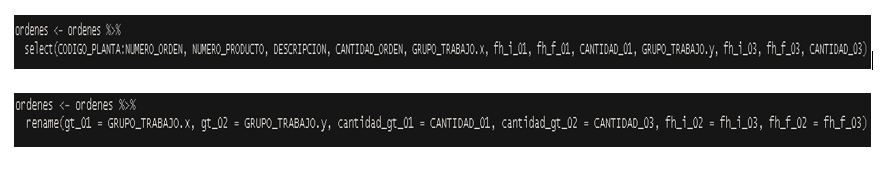
6.3.3 Seleccionar y Renombrar columnas
En este punto, vamos a quedarnos con las columnas que vamos a utilizar posteriormente y vamos a renombrar los encabezados para una mayor comprensión
6.3.4 Añadir Columnas de Tiempos
Vamos a crear 3 nuevas columnas, una con el tiempo total dedicado a la orden, que será la resultante de la suma de las otras dos columnas, T_01 y T_02, que serán el tiempo total dedicado por el primer grupo de trabajo y el tiempo total dedicado por el segundo grupo de trabajo respectivamente.
Por lo tanto, en este momento la tabla de órdenes, tiene la siguiente estructura:
- CODIGO_PLANTA: hace referencia al código de la planta donde se realiza la orden.
- CODIGO_LINEA: hace referencia al código de la línea donde se realiza la orden.
- NUMERO_ORDEN: hace referencia al número de orden de producción realizada.
- NUMERO_PRODUCTO: hace referencia al número de producto fabricado en la orden.
- DESCRIPCION: hace referencia a la descripción del producto fabricado en la orden.
- CANTIDAD_ORDEN: hace referencia a la cantidad a fabricar.
- gt_01: hace referencia al código del primer grupo de trabajo que participó en la orden.
- fh_i_01: hace referencia a la fecha y hora inicial en la que el primer grupo de trabajo comenzó a participar en la orden.
- fh_f_01: hace referencia a la fecha y hora final en la que el primer grupo de trabajo terminó de participar en la orden.
- cantidad_gt_01: hace referencia a la cantidad total que el primer grupo de trabajo fabricó en la orden.
- gt_02: hace referencia al código del segundo grupo de trabajo que participó en la orden.
- fh_i_02: hace referencia a la fecha y hora inicial en la que el segundo grupo de trabajo comenzó a participar en la orden.
- fh_f_02: hace referencia a la fecha y hora final en la que el segundo grupo de trabajo terminó de participar en la orden.
- cantidad_gt_02: hace referencia a la cantidad total que el segundo grupo de trabajo fabricó en la orden.
- T_01: hace referencia al tiempo total empleado por el primer grupo de trabajo a la orden
- T_02: hace referencia al tiempo total empleado por el segundo grupo de trabajo a la orden
- TIEMPO_TOTAL: es el tiempo total dedicado a la orden por ambos grupos de trabajo
6.4 Calculo de tiempos por producto
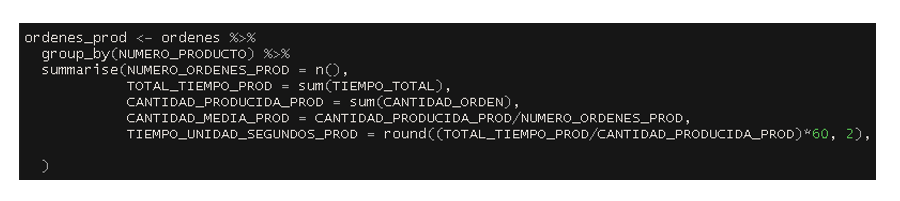
Vamos a crear otra variable llamada ordenes_prod en la que haremos un resumen de los tiempos dedicados por producto que se ha fabricado durante el año. La nueva variable contendrá una tabla con los siguientes campos:
- NUMERO_PRODUCTO: hace referencia al código de producto a analizar
- NUMERO_ORDENES_PROD: hace referencia al número total de órdenes realizadas de dicho producto
- TOTAL_TIEMPO_PROD: hace referencia al tiempo total dedicado al producto
- CANTIDAD_PRODUCIDA_PROD: hace referencia al total de la cantidad producida de dicho producto
- CANTIDAD_MEDIA_PROD: hace referencia a la cantidad media por orden
- TIEMPO_UNIDAD_SEGUNDOS_PROD: hace referencia a la media de tiempo en segundos dedicada a cada producto
6.5 Calculo de tiempos por Grupo de Trabajo
En este punto, vamos a proceder a calcular tiempos por Grupo de Trabajo. Para ello, hemos de realizar 3 pasos:
6.5.1 Dividir la tabla de órdenes de producción por un grupo de trabajo
Se han de diferenciar las órdenes en las que ha intervenido un grupo de trabajo y en cuáles han intervenido dos, almacenando en dos variables diferentes:
- ordenes_gt_01: todas las órdenes, ya que en todas han participado al menos un grupo de trabajo
- ordenes_gt_02: sólo las órdenes en las que ha participado un segundo grupo de trabajo

En ambas tablas, renombramos los campos, siendo GT el futuro campo clave de la tabla.
6.5.2 Unir las tablas generadas
Se va a proceder a unir, con un unión_all las tablas que generamos en el punto anterior. Lo almacenaremos en una variable llamada ordenes_gt. De este modo, tendremos el total de ordenes en las que han participado todos los grupos de trabajo y siendo la clave de la tabla la unión de las columnas GT y NUMERO_PRODUCTO

6.5.3 Calcular los tiempos por Grupo de Trabajo
Vamos a crear otra variable llamada ordenes_gt_prod en la que, como se dijo en el punto anterior, el campo clave es la unión de GT y NUMERO_PRODUCTO de modo que agruparemos por estas dos columnas para hacer los cálculos:

Como podemos observar, la tabla resultante del código anterior, contiene los siguientes campos:
- GT: hace referencia al grupo de trabajo
- NUMERO_PRODUCTO: hace referencia al número de producto
- NUMERO_ORDENES_GT_PROD: hace referencia al número de órdenes realizadas por ese grupo de trabajo por producto
- TOTAL_TIEMPO_GT_PROD: hace referencia al tiempo total dedicado por ese grupo de trabajo para fabricar dicho producto
- CANTIDAD_PRODUCIDA_GT_PROD: hace referencia a la cantidad total del producto producida por el grupo
- CANTIDAD_MEDIA_GT_PROD: hace referencia a la cantidad media de producto producida por ese grupo de trabajo
- TIEMPO_UNIDAD_SEGUNDOS_GT_PROD: hace referencia al tiempo en segundos dedicado por grupo de trabajo para una unidad de producto.
6.6 Medir la eficacia en función de los tiempos medios
Para hacer una medición de la eficacia de cada grupo de trabajo, vamos a calcular la diferencia de los campos de TIEMPO_UNIDAD_SEGUNDOS_GT_PROD, que hace referencia al tiempo en segundos dedicado por grupo de trabajo para una unidad de producto, y el campo TIEMPO_UNIDAD_SEGUNDOS_PROD, que hace referencia a la media de tiempo en segundos dedicada a cada producto. De este modo, podremos ver cuánto se desvía el grupo de trabajo respecto de la media de todos los grupos de trabajo de la compañía. Haremos esto para cada producto y finalmente calcularemos la eficacia acumulada para todos los productos (eficacia_acum).
Cabe decir que, a mayor sea el número de la eficacia_acum, menos eficaz será el grupo de trabajo

6.7 Eficacia en función del tipo de Grupo de Trabajo
Una vez sacada la eficacia acumulada, vamos a ver a qué tipo de grupo de trabajo, cuanto a sus características, corresponde dicha eficacia. Es decir, vamos a ver, en función de la antigüedad, sexo y edad, cuáles son los grupos de trabajo más eficientes. Lo haremos con el siguiente código:

El resultado final que obtenemos es el siguiente, que explicaremos a continuación:
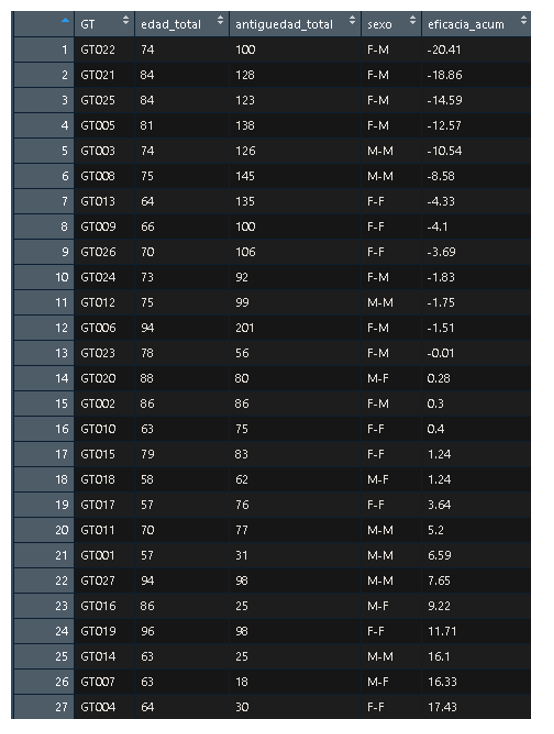
- GT: hace referencia al código del grupo de trabajo
- edad_total: hace referencia a la suma de edades de los miembros del grupo de trabajo
- antigüedad_total: hace referencia a la suma de antigüedad de los miembros del grupo de trabajo
- sexo: hace referencia a la combinación de sexos de los miembros del grupo de trabajo
- eficacia_acum: hace referencia a la eficacia acumulada durante todo el año del grupo de trabajo
6.8 Representación Gráfica
Para una mayor comprensión de los datos obtenidos, vamos a realizar una representación gráfica de los mismos. Para ello, ejecutamos las siguientes líneas de código:

El resultado de este código son los siguientes gráficos:
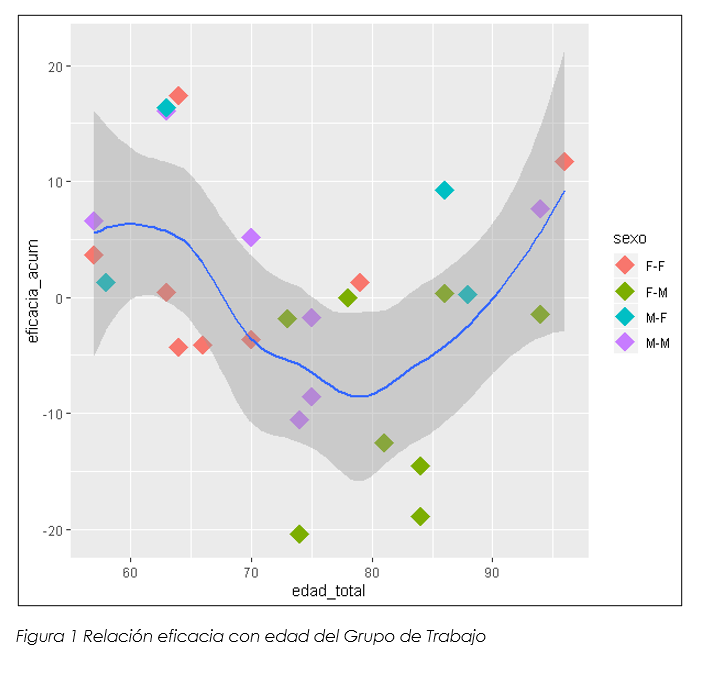
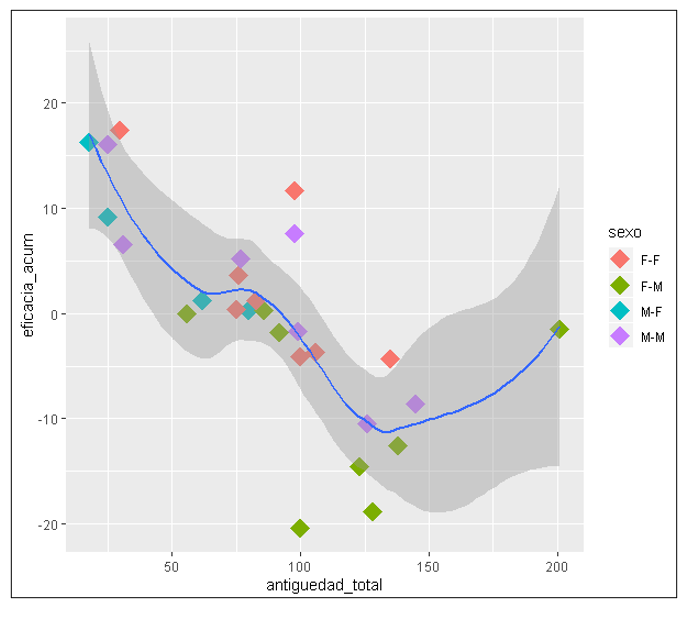
6.9 Conclusiones de los datos
Tras el tratamiento de los datos históricos de fabricación de la compañía, tenemos 3 variables (edad, sexo y antigüedad) que nos pueden hacer llegar a las siguientes conclusiones:
- En lo que al sexo se refiere, Los grupos de trabajo formados por Hombre-Mujer, son mucho más eficientes que los grupos de trabajo formados por Hombre-Hombre o Mujer-Mujer.
- Los grupos de trabajo con mayor antigüedad en la compañía, generalmente, son más eficientes que aquellos con menor antigüedad.
- En cuanto a la edad, los grupos de trabajo con edades medias (ni muy mayores ni muy viejos) son más eficientes que el resto.
7. Conclusión
Tras la finalización del proyecto, revisaremos los objetivos marcados al principio para ver si hemos cumplido con ellos:
- Eliminar duplicidades en el proceso de producción de la compañía
- Este primer objetivo se ha cumplido, ya que, gracias a la implementación de la APP, se ha liberado de trabajo administrativo y se han eliminado pasos del proceso que no aportaban valor.
- Tener datos a tiempo real
- Gracias a la implementación de la APP nuevamente y a la Base de Datos, cualquiera puede consultar datos a tiempo real de la producción de PackSnack SL.
- Eliminar posibles errores en el proceso
- Gracias a eliminar la duplicidad de escribir datos, se logran eliminar errores.
- Fijación de tiempos estándar que nos sirvan de base para la posterior planificación y programación de la producción.
- Este objetivo está resuelto en el punto 6.5.3 Calcular los tiempos por Grupo de Trabajo, del presente documento
- Generar insights para el establecimiento e implantación de sistemas de incentivos para los operarios, una vez definidos los tiempos medios.
- Gracias a la tabla del punto 6.7 Eficacia en función del tipo de Grupo de Trabajo del presente documento, la compañía podrá incentivar como tenga a bien los niveles de eficiencia de sus operarios de fábrica
Referencias
Autor: Desconocido. ¿Qué es el Big Data? ¿En qué consiste el almacenamiento masivo de datos?. Fecha Desconocida, de UNITEL Soluciones e Infraestructuras Tecnológicas Sitio web: https://unitel-tc.com/QUE-ES-EL-BIG-DATA/
Autor: Desconocido. Macrodatos. Fecha Desconocida, de WIKIPEDIA Sitio web: https://es.wikipedia.org/wiki/Macrodatos
Barranco Fragoso, R. ¿Qué es Big Data?. Junio 18, 2012, de IBM Developer Sitio web: https://developer.ibm.com/es/articles/que-es-big-data/
Autor: Desconocido. Big Data: de la teoría a la práctica > 1. ¿Qué es el Big Data?. Agosto 11, 2018, de MHP Software Sitio web: http://mhp-net.es/big-data-teoria-practica-1-que-es/
Autor: Desconocido. El origen del Big Data. Septiembre 14, de Big Data International Campus Sitio web: https://www.campusbigdata.com/big-data-blog/item/106-origen-big-data
Autor: Desconocido. Big Data: desde los inicios hasta hoy. Enero 23, 2018, de Ideas Para tu Empresa Sitio web: https://ideasparatuempresa.vodafone.es/big-data-desde-los-inicios-hoy/
Autor: Desconocido. Sistemas de Soporte a la Decisión (DSS). Fecha Desconocida, de Sinnexus Sitio web: https://www.sinnexus.com/business_intelligence/sistemas_soporte_decisiones.aspx
Autor: Desconocido. ¿Qué es el Business Intelligence?. Fecha Desconocida, de Sinnexus Sitio web: https://www.sinnexus.com/business_intelligence/
Autor: Desconocido. ¿Qué es Business Intelligence (BI) y qué herramientas existen?. Octubre 5, 2017, de SIGNATURIT Sitio web: https://blog.signaturit.com/es/que-es-business-intelligence-bi-y-que-herramientas-existen
Autor: Desconocido. Ciencia de datos. Fecha Desconocida, de WIKIPEDIA Sitio web: https://es.wikipedia.org/wiki/Ciencia_de_datos
González Sojo, D. W. AMPLIACIÓN DE SIMULADOR DE RED. INTERFAZ GRÁFICA DEL QSIM. Julio, 2006, de biblioteca escuela ingenieros sevilla Sitio web: http://bibing.us.es/proyectos/abreproy/11300/fichero/PROYECTO%252FCapitulo3.pdf
Autor: Desconocido. Tkinter: interfaces gráficas en Python. Diciembre 25, 2015, de Python 3 para impacientes Sitio web: https://python-para-impacientes.blogspot.com/2015/12/tkinter-interfaces-graficas-en-python-i.html
Autor: Desconocido. Tipos de Bases de Datos y sus Usos. Fecha Desconocida, de Tecnologías-Información Sitio web: https://www.tecnologias-informacion.com/basesdedatos.html
Autor: Desconocido. CRUD: la base de la gestión de datos. Septiembre 4, 2019, de IONOS Sitio web: https://www.ionos.es/digitalguide/paginas-web/desarrollo-web/crud-las-principales-operaciones-de-bases-de-datos/
Velasco, R. DB Browser for SQLite, la forma más fácil de crear y editar bases de datos SQLite. Junio 30, 2018, de Redes Zone Sitio web: https://www.redeszone.net/2018/06/30/db-browser-sqlite-bases-datos/
pildorasinformaticas (Díaz, J.) . Curso Python desde 0. Enero 24, 2017, de Youtube Sitio web: https://www.youtube.com/playlist?list=PLU8oAlHdN5BlvPxziopYZRd55pdqFwkeS
Jesús Conde (Conde, J.). Convertir de Python 3 a ejecutables .exe. Agosto 2, 2014, de Youtube Sitio web: https://www.youtube.com/watch?v=Ro4z4xFhlo4
Gomila Salas, J.G. & Frogames SL. Curso completo de R para Data Science con Tidyverse. Fecha Desconocida, de Udemy Sitio web: https://www.udemy.com/course/r-for-data-science/
Tunnell, S & Equipo Datademia. Curso de R para Ciencia de Datos - Maneja tus datos con R. Fecha Desconocida, de Udemy Sitio web: https://www.udemy.com/course/r-developer-big-data-con-r/
Los más leídos
ADRIÀ NOLLA DEL VALLE, (2023)
La Cartera Adaptada: adaptando la cartera permanente a los ciclos económicos Leer InvestigaciónAlberto Conchillo Guantes, (2023)
Impacto del impuesto de sociedades en el comportamiento de las empresas Leer InvestigaciónFrancisco Javier Roldán de la Rosa, (2023)
Historia y evolución de la Farmacovigilancia Leer Investigación
Relacionados Informática y TICS
- Data Science y Recursos Humanos: implementando el HR Analytics
- Competitividad & Desarrollo (Perspectiva Descriptiva & De Correlación)
- Tecnología y sus efectos en nosotros
- Análisis del impacto del subsector de la restauración en la contratación del sector turístico en Andalucía. Un estudio por provincias y municipios de la Comunidad Autónoma Andaluza
- Diseño e implementación de un Datawarehouse en una cadena de tintorerías y lavanderías
- Analizando la cadena de bloques en materia de ciberseguridad con diseño de un “smart contract” para el despliegue de token criptográfico y su uso con transacciones sobre “Wallets” para el conjunto de empleados de una organización sobre Blockchain Pública
- Estudio, análisis y desarrollo de herramientas de las distintas fases del hacking ético
- Hacking Ético en Redes Wifi
- Yaaseen Oman: desarrollo y puesta en producción de una aplicación web
- Aplicación de Voronoi en algoritmos no supervisados de Machine Learning con análisis geoespacial

